

一.有关ROS#
1.工作空间的创建#
mkdir - p xxx_ws/src
cd xxx_ws/
catkin_make进入工作空间并启动vscode
cd xxx_ws
code .2.检查cv_bridge的版本和卸载#
检查版本
rospack find cv_bridge若报错:[rospack]Error:package’cv_bridge’not found
则不需要卸载
卸载命令:
sudo apt-get remove ros-noetic-cv-bridge3.鱼香ROS命令#
主命令:
wget http://fishros.com/install -O fishros && . fishros视情况选择数字,初次安装必选1
4.launch文件#
选定功能包右击新建launch文件夹
选定launch文件夹右击添加launch文件.launch (.xml)
编辑launch文件内容#
node–>包含的某个节点
pkg–>功能包名
type–>被运行的节点文件
name–>为节点命名
output–>设置日志输出目标(可选)
二.opencv安装、编译和验证(以4.6.0.66为例)#
1.opencv-cpp的下载和编译#
挂梯子,直接去官网的library ->release找到4.6.0的source直接下载
解压到主目录,此时会看见一个opencv-4.6.0的文件夹,先别急着编译
安装编译依赖!
sudo apt update
sudo apt install build-essential cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
sudo apt install libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libdc1394-22-dev
sudo apt install libeigen3-dev libtheora-dev libvorbis-dev libxvidcore-dev libx264-dev sphinx-common
sudo apt install yasm doxygen libfaac-dev libopencore-amrnb-dev libopencore-amrwb-dev libopenexr-dev
sudo apt install libgstreamer-plugins-base1.0-dev libavutil-dev libavfilter-dev libavresample-dev 当你卸载了opencv-cpp或者需要重新catkin_make时(例如打开cuda-opencv),这一步需要重新安装编译依赖
2.准备编译环境#
cd ~/opencv-4.6.0
mkdir build
cd build 3.编译命令#
cmake -D CMAKE_BUILD_TYPE=Release -D OPENCV_GENERATE_PKGCONFIG=YES .. 上面这条语句会默认生成opencv.pc并写入正确的目录,不需要手动nano创建
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local .. 这条就不行,不推荐
make -j$(nproc)使用你cpu最大线程数进行编译(并向)。
AMD处理器编译时有概率会出现卡顿,如果一直卡着请重新编译,这是AMDcpu架构的问题
4.安装#
sudo make install5.更新动态链接库缓存(可选)#
sudo ldconfig验证安装有三个手段,最好都试一下
1.直接输入命令
pkg-config --modversion opencv4 观察版本号是否能被正确输出
2.在opencv-4.6.0文件夹中,opencv/samples/cpp/example_cmake 并把它在终端中打开,输入:
cmake .
make
./opencv_example若无报错且正确弹出window:Hello OpenCV 安装成功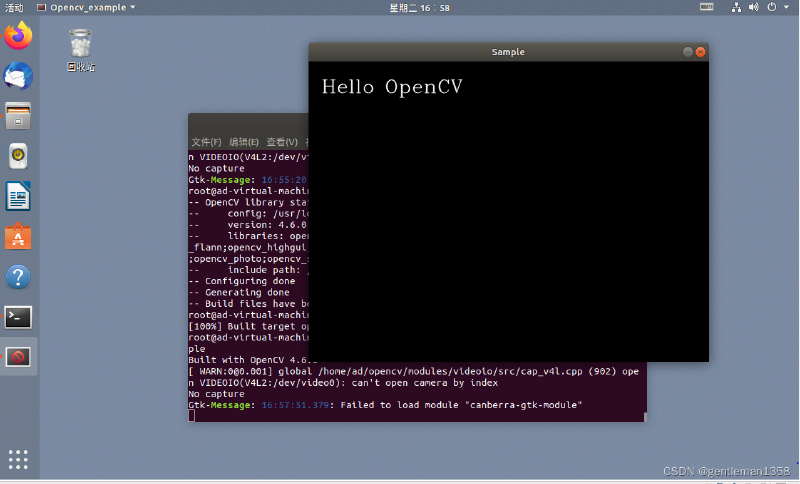
3.验证opencv.pc文件
命令:
ls /usr/local/lib/pkgconfig -name "opencv*.pc" 若能正确找到,安装成功
若不能,可能需要手动nano创建
三.opencv-python的安装#
pip install opencv-python==4.6.0.66 ez
验证
python3
>>>import cv2
>>>print(cv2.__version__) 四.当完成cpp和py的安装后应验证#
当你完成cpp和py的安装,应新建一个工作空间以验证ROS和Cmake是否能被正确编译
这一步应该先于卸载和安装cv-bridge
五.opencv-bridge安装#
首先确认ROS自带的bridge有没有被卸载干净
1.添加opencv4环境变量#
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfigGitHub上搜索ROS的vision_opencv,选择noetic版本 code fork到本地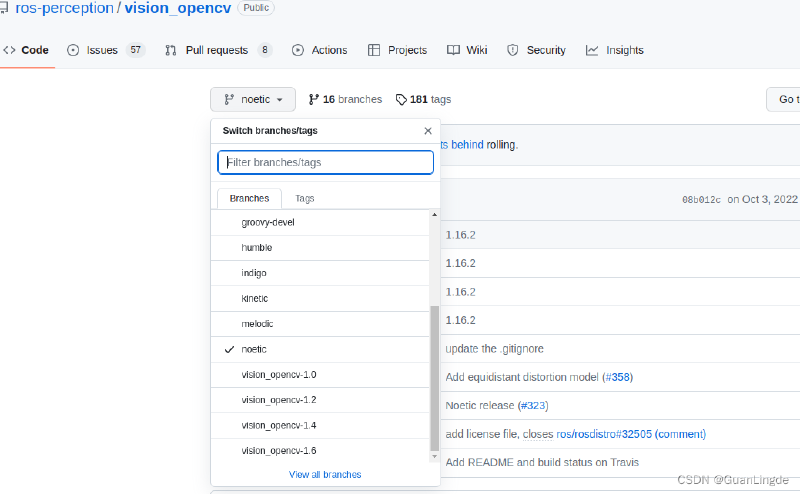
创建一个新的工作空间bridge_ws ,并camke,将cv-bridge解压到src目录下,并更改其CmakeList.txt
找到并更改
find_package(OpenCV 4.6.0 REQUIRED) 保存
最好是把pkg.xml的cv_name也改一下,不过不改也无所谓
2.重新编译cv_bridge#
cd ~/your_catkin_ws
catkin_make clean
catkin_make cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=F:\opencv\sources\bulid\release此时大概率报错(若正常请忽略)
:~/new_catkin_ws$ catkin_make clean Base path: /home/owen/new_catkin_ws Source space: /home/owen/new_catkin_ws/src Build space: /home/owen/new_catkin_ws/build Devel space: /home/owen/new_catkin_ws/devel Install space: /home/owen/new_catkin_ws/installRunning command: “cmake /home/owen/new_catkin_ws/src -DCATKIN_DEVEL_PREFIX=/home/owen/new_catkin_ws/devel -DCMAKE_INSTALL_PREFIX=/home/owen/new_catkin_ws/install -G Unix Makefiles” in “/home/owen/new_catkin_ws/build”– Using CATKIN_DEVEL_PREFIX: /home/owen/new_catkin_ws/devel – Using CMAKE_PREFIX_PATH: /home/owen/new_catkin_ws/devel;/opt/ros/noetic – This workspace overlays: /home/owen/new_catkin_ws/devel;/opt/ros/noetic – Found PythonInterp: /usr/bin/python3 (found suitable version “3.8.10”, minimum required is “3”) ……
该错误说明无法找到boost_python库
安装指令
sudo apt-get update #更新
sudo apt-get install libboost-python-dev libboost-python1.71.0 再次编译
六.深度学习环境安装#
1.nVidia显卡驱动安装#
首先确保你的电脑在独显直连模式上,其次必须是nv显卡。
因为ubuntu会给nVidia显卡一个默认驱动,所以我们需要安装nv自己的驱动以完成后续的工作。
首先更新你的软件
sudo apt-get update
sudo apt-get upgrade 查看驱动推荐:
ubuntu-drivers devices 推荐自动安装
sudo ubuntu-drivers autoinstall 手动安装会触发Secure Boot,不推荐
重启
sudo reboot 如果正常安装应该可以重启,否则不能重启,会卡在读取界面(不要问我怎么知道的)需要进入recovery界面删除新驱动换回默认驱动,这里会比较麻烦
重启后运行nvidia-smi命令,观察驱动版本号和最高支持的cuda版本
这里以RTX 4060为例,驱动版本535,cuda最高支持12.2
tips:可以试试你的电脑能否调节亮度,如果可以,那也算是安装好了
2.cuda安装(11.1)#
首先应确定pytorch支持什么版本的cuda再安装,这里以11.1cuda为例
去nv官网搜索cuda11.1 toolkit 选择Linux ->x86_64 ->ubuntu ->20.04 ->runfile(local)
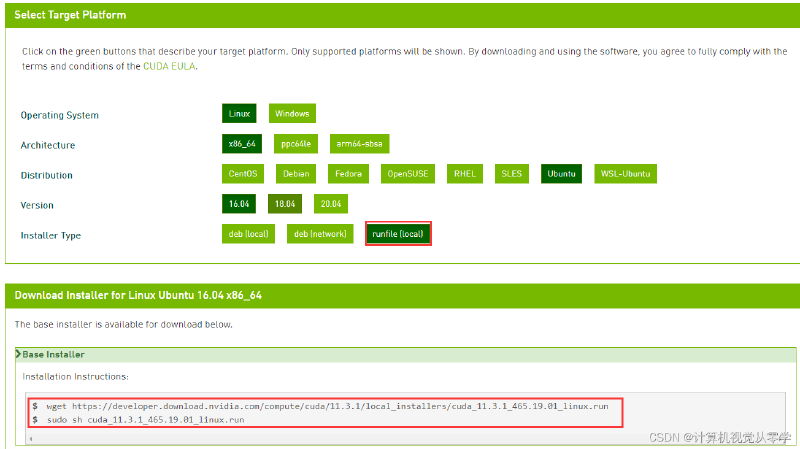
copy下面出现的命令
一般是wget…….
sudo sh cuda…..
自行安装 会比较慢
sh过程中会弹出cuda的安装器,直接continue ->accept 最后取消勾选driver(第一个) 因为前面我们已经装过了,下面四个勾上,如果让你选择yes or no全选yes,install按回车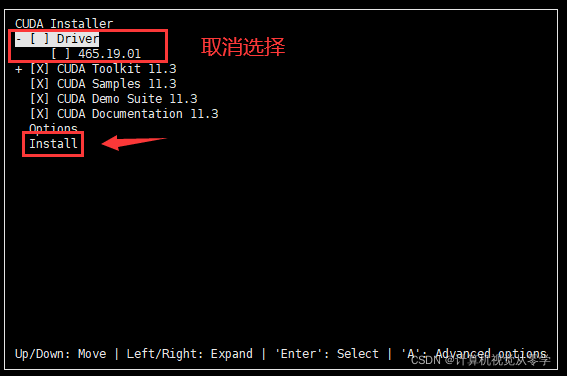
等待…….
3.配置环境变量#
进入根目录
cd ~
nano .bashrc #用nano或是gedit打开bashrc文件,尽量不去碰vim 在文末添加
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:/usr/local/cuda/extras/CPUTI/lib64
export CUDA_HOME=/usr/local/cuda/bin
export PATH=$PATH:$LD_LIBRARY_PATH:$CUDA_HOME 保存(ctrl+o)
echo 'export PATH=/usr/local/cuda-11.1/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-11.1/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc #刷新 退出(ctrl+x)
4.检查是否安装完成#
nvcc -V(大写)
如果正确输出五行并且打印版本正确就行了
可以看看你安装的四个软件是否在软件目录中

5.pytorch安装(1.8.1 cuda加速版本)#
确认已经安装正确的cuda全家桶 ,驱动也安装完毕
进入pytorch官网搜索pytorch1.8.1
一定要使用pip安装方式!!! 不要瞎搞conda
更新pip
pip install --upgrade pip找到cuda11.1版本的pip安装方式,在终端键入命令
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html等待安装完成
终端键入
python3 -c "import torch; print(torch.cuda.is_available())" 若输出True,则安装完毕
若False,重装
七.ultralytics相关的准备#
主要会介绍yolov5和yolov8两种模型的本地部署和训练,此篇内容较简单,具体操作请查阅官方文档https://docs.ultralytics.com/zh
1.yolov5的本地部署和训练#
确保在你的根目录下
git clone https://github.com/ultralytics/yolov5 # clone repository
cd yolov5
pip install -r requirements.txt # install dependencies 直接在github上克隆下载整个文件夹 训练
命令:
python3 train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml --batch-size 128 该命令仅供参考
epochs:训练轮数
weights:权重
yolov5n:所使用的神经网络模型类型
batch-size:一批量的照片数量(请根据显卡显存以及所选神经网络模型类型决定,宁小勿大)
除此之外,你还需指定数据集的路径等等,此篇概不赘述,官方文档有详细解答
用detect进行推理
命令:
python3 detect.py --weights yolov5s.pt --source img.jpg 脚本 detect.py 用于对各种来源进行多功能推理。它能自动获取 模型 从最新的YOLOv5 释放 并轻松保存结果。
warning:本文只是概述了yolov5模型的使用,但绝不代表其功能仅限于此,请务必查阅官方文档了解更多
2.yolov8和ultralytics软件包#
本地部署:
pip install ultralytics
具体功能查阅
https://github.com/ultralytics/ultralytics
https://github.com/ultralytics/assets/releases/tag/v8.2.0
与yolov5有所不同
图片均来自网络,若有侵权请联系作者删除
该博客指南专用于笔者实验室指导
如遇Linux安装问题请访问
https://blog.anawaert.com/post/tittle-tattle/installation-of-ubuntu/